




著者:Criteo チーフ AI アーキテクト、Flavian Vasile
この記事で伝えたいこと
レコメンドシステムは、デジタルコマースを動かす“見えないエンジン”となり、人々が何を見て、何を買い、そしてお金がどこに流れるかに影響を与えています。かつては単なる機能だったものが、今ではエンゲージメント、コンバージョン、そして成長を牽引する中核インフラになっています。
しかし、コマースのさらなる進化に必要なのは、商品レコメンドの改良ではありません。行動や取引データに基づくディープラーニングにようる高精度なレコメンドと、大規模言語モデル(LLM)の会話インテリジェンスを組み合わせたハイブリッド型のシステムが、予測するだけでなく、理解し、推論し、説明能力を備え、精度と信頼で消費者をガイドするインテリジェントなエージェントを生み出します。
この改革で先頭を走るのが Criteo です。毎日7億2千万人の消費者データ、年間1兆ドルを超えるの取引データ、17,000社の広告主ネットワークにアクセスできる Criteo は過去20年にわたり、膨大なデータを扱いった成果を重視したレコメンド技術を磨き上げてきました。DeepKNN や MetaProd2Vec、Causal Embeddingsのような革新的な技術から、最先端の反実仮想学習や因果モデリングまで、私たちは業界を支えるパフォーマンスの基盤の確立に貢献してきました。
Criteo では現在、パフォーマンスと対話を一つのハイブリッドフレームワークに統合するための土台を築いています。パフォーマンスに照準を合わせた商品レコメンド・エージェントは意図を解釈して、最適化された結果を取得し、その理由を自然言語で説明できます。このため、関連性や成果、信頼性がつながり、循環する仕組みが完成します
これは単なる技術の変化ではありません。AI が商品の発見を促し、信頼がエンゲージメントを支え、ハイブリッドシステムが成功を左右する、そんな新しいコマースの基礎なのです。
インフラとしての商品レコメンド
レコメンドシステム(小売サイトで商品を提案したり、Netflix でおすすめ作品を表示したり、Spotify でプレイリストを提案したりする AI エンジンやアルゴリズム)はデジタルコマースの屋台骨となりつつあります。レコメンドシステムという言葉を知らなくても、誰もが毎日このシステムを多用しています。
Criteo の立ち位置はいたってシンプルです。商品レコメンドはもはや単なる”機能”ではなく、”インフラ”です。消費者の選択に影響を与え、商品の発見を促進し、購買行動を導くする存在ーーービジネスにとって、レコメンドシステムは追加オンオプションではなく、必須なものなのです。エンゲージメントやコンバージョン率、ロイヤルティの向上、マーケティング投資の効率化など、目に見える成果を促進してくれるドライバーであり、今日の経済においてスケーラブルなレコメンド性能は、単なる便利さではなく、競争力そのものなのです。
ただし、レコメンドの進化は、もはや単独のシステムだけでは実現できません。それを実現するのは、レコメンドシステムの確かなパフォーマンスと、LLM(大規模言語モデル)の会話インテリジェンスを融合したハイブリッド型です。。この技術は、消費者の情報探索や意思決定のあり方を急速に変えています。
会話型 AI がコマースに浸透し始めていることを示す最近の事例に、Shopify や Etsy と OpenAI との提携があります。同社のアプローチは構造化された商品フィードに基づくものですが、そのような仕様であっても、ランキングを改善するために人気スコアや返品率といったパフォーマンス指標の提供がマーチャントに求められています。つまり、会話型コマースにおいても、コンテンツだけでは不十分ということです。レコメンドシステムは、どの商品を強調表示するかを判断するために、成果に基づくシグナルを必要とします。
このようなパートナーシップは方向性としては正しいのですが、より広いコマースエコシステム全体に規模を拡大する上では不十分です。ここでは、ハイブリッドシステムが今後を左右する理由と、Criteo の専門知識と規模が、その構築において特別な優位性を提供する理由を説明します。
深層学習レコメンドシステムの台頭
すべてのレコメンドシステムが同じように作られているわけではありません。初期のレコメンドシステムは「この商品を買った人は、このような商品も購入しています」といった単純なパターンに重点を置いていました。ルールや浅いモデルに依存していたため、複雑なカスタマージャーニーや膨大な商品カタログには対応しきれませんでした。
ここ10年の間に新たなシステムクラス「深層学習ベースのレコメンドシステム」が台頭。これらのモデルでは、ディープラーニングを活用し、はるかに充実した消費者行動パターンを補足します。単に「一緒に購入された商品」のシグナルに頼るのではなく、クリック数、検索数、購入数などの数十億件に及ぶ膨大なイベントの連続から学習します。関連性だけでなく、売上ランキングの正確性や ROI、顧客生涯価値(LTV)といった高度なビジネス目標の達成に向けて直接最適化します。十分なデータがあれば、これらのモデルは希少な価値を提供します。それは、予測可能なパフォーマンスです。データが十分にあれば、成果を確実かつ測定可能に改善し、企業が信頼できる基盤となります。
Criteo はまさにこの分野のパイオニアとして、画期的なデータセットをリリースし、埋め込みベースのモデルを進化させ、さらに自社のディープラーニング型レコメンドシステム「DeepKNN」など、実運用システムで高い評価を獲得してきました。
Criteo のイノベーション実績
Criteo は過去20年間で大規模なパフォーマンス・レコメンドを築いてきました。1日あたり7億2千万人の消費者行動を解析し、年間コマース取引総額は1兆ドルに至ります。また、世界17,000の広告主クライアントに利用されており、その中には230社のリテーラーと4,000のブランドが含まれます。この規模の大きさにより、弊社のレコメンドシステムはコマースエコシステム全体でトレーニングと展開を行うことができ、完全な多対多のアーキテクチャ(複数の要素同士が相互に結びつく構造)でリテーラー、ブランド、プラットフォームをつないでいます。
Criteo が誇るのは規模だけではありません。弊社は MetaProd2Vec のような提案を通じて、商品埋め込みg術を早期に導入ました。また、1TB Click Logs Dataset という画期的な技術をリリースして、DeepKNN などの受賞歴(2024年、SBR Technology Excellence Award)のあるプロダクトシステムを構築しました。こうした実用面でのブレークスルーは、NeurIPS、ICML、ICLR、RecSysといったトップカンファレンスでの理論的貢献によって継続的に裏付けられています(詳細はCriteo AI Labの公開論文をご覧ください)。
当社の最大の強みのひとつは、パフォーマンスを最適化したレコメンドにおけるリーダーシップです。実際の環境でのユーザー行動から直接学習することで、適応と改善を繰り返し、短期的なエンゲージメントと長期的な価値の両方を最大化するレコメンドを実現しています。2018年の Causal Embeddings(因果埋め込み)や、2020年のDistributionally Robust Counterfactual Learning(分布にロバストな反実仮想学習)といった初期の進化から、2024年の最新のオフポリシー評価・学習手法など、Criteo は、コマースシグナルに基づいてレコメンドシステムを直接トレーニングすることで、ログされたインタラクションをよりスマートで適応性が高く、深くパーソナライズされた成果へと変革できることを示してきました。
また、REVEAL(2018~2022年)や CONSEQUENCES(2022年~現在)のような長期的なワークショップにより、世界全体で協力して解決すべき重要な課題のひな型を作り、レコメンドシステムの因果推論やカウンター・ファクチュアル評価、逐次的意思決定、長期的価値モデリングの方法を進化させています。
レコメンド・エージェントの台頭
一方、LLM も新たな境地を切り開きました。LLM の特長は何と言っても「対話」です。複雑なリクエストを解釈し、状況を明確に把握するための質問をして、選択した内容について自然言語で説明します。これにより、最新のレコメンドシステムに欠けている交流や透明性、回答の質を確保するのです。
ただし、LLM 自体はコマース向けに設計されていません。ショッピングデータに接続することもできませんし、ビジネス成果に向けて最適化も行いません。とはいえ、その強みである対話と説明は、商品レコメンドシステムを補完するには理想的な要素です。弊社がハイブリッドな商品レコメンドの未来に期待を寄せる理由は、ここにあります。
レコメンドシステムはパフォーマンスの向上と規模の拡大を、LLM は対話と信頼性をもたらします。この2つを組み合わせることで、効果的で説明に長けたシステムを構築できるのです。これにより、Criteo が重点的に取り組んできた目標、「商品レコメンドシステムと LLM を新たなコマースの基盤に統合し、パフォーマンス最適化されたレコメンド・エージェントを構築すること」を達成できます。
共通するDNA:LLMとレコメンドシステム
一見すると、レコメンドシステムと LLM はまったく異なるテクノロジーのように見えます。しかしどちらも根幹は同じ。膨大な人間の行動データを基にトレーニングされたシーケンスモデルなのです。
以下の2つの図(図1と2)は、レコメンドシステムと LLM の間の概念的な対称性を示しています。どちらも膨大な人間の行動記録を基にトレーニングされたシーケンスモデルであり、一方は「次に購入する商品」を、もう一方は「次に来る単語」を予測します。
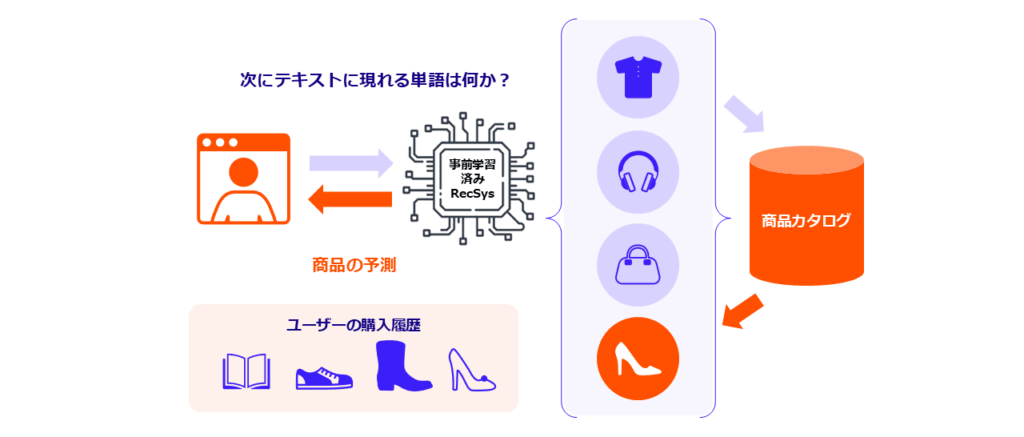
図1:ショッピング・シーケンスを予測するレコメンドシステム:レコメンドシステムでは、ユーザーの閲覧履歴や購入履歴を「商品とのインタラクションのシーケンス」として扱います。事前にトレーニングされたレコメンドモデルは、更新され続ける膨大な商品カタログの中から、ユーザーが次に閲覧または購入しそうな商品を予測することを学習します。クリックや購入のたびに、ユーザーの行動「言語」を絞り込み、システムが意図や好みの変化のパターンを時間とともに学習していきます。
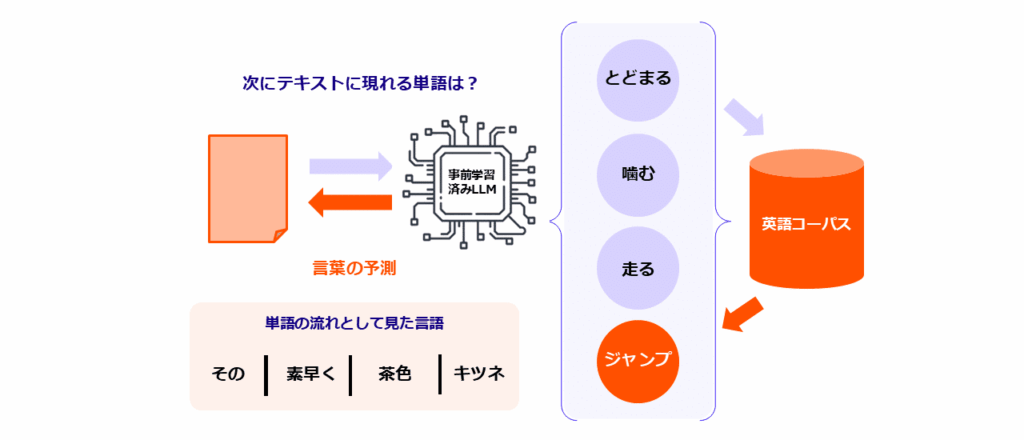
図2:テキストシーケンスを予測する大規模言語モデル(LLM):言語モデルでは、文章を「単語の羅列」として扱います。事前にトレーニングされた LLM は、膨大なテキストコーパスから学習したパターンを活用し、前後の文脈に基づいて次に来る単語を予測します。レコメンドが次の関連アイテムを予測するのと同じように、LLM は言語の連続性から意味を拡張し、一貫性と関連性を保てるよう最適化します。
この類似性こそが、レコメンドシステムをLLMのパラダイムを理解し、適応し、さらに拡張するうえで非常に有利な立場に置いています。また、両者を組み合わせることが可能なだけでなく自然である理由でもあります。 両者は同じ2つのフェーズを持っています:
- 事前学習(Pre-training)により、広大な「言葉の地図」を作り、次の言葉や関連商品を予測します。
- ファインチューニング(Fine-tuning)で、マッピングされた情報を特定の目的に適応させます。OpenAI 発表した、ChatGPT の人間からのフィードバックを利用した強化学習に関するリサーチでも示されている通り、LLM は人間の嗜好判断を利用します(2022年、Ouyang 他)。また、レコメンドシステムは Bayesian Personalized Ranking(BPR、ベイズ的パーソナライズ順位付け)のようなレコメンド・アルゴリズムなどの手法を用い、クリックやコンバージョンのようなビジネスシグナルを活用します(2009年、Rendle他)。
この共通基盤があるため、両分野の専門家は容易にクロスオーバーできます。レコメンドシステムに深い専門性を持つ企業にとって、これは戦略的な優位性となります。
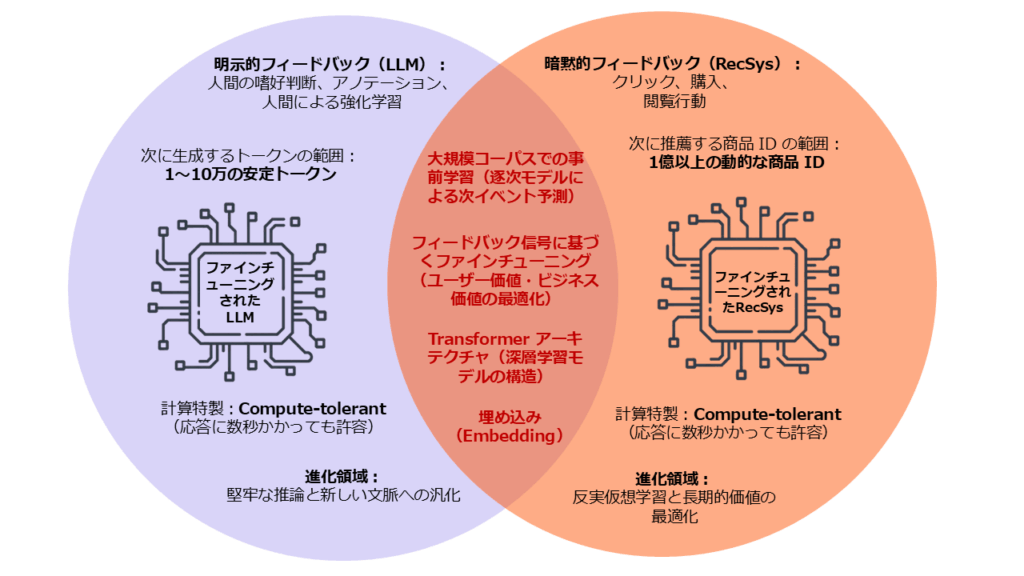
図3:共通するDNA、異なる課題: LLM とレコメンドシステムはどちらも、埋め込み、トランスフォーマー、ファインチューニングを基に構築されたシークエンスモデルですが、フィードバック信号、アイテム空間、そして研究の方向性において異なる進化を遂げています。
なぜコマースにおけるアライメントは難しく、価値が高いのか
LLM にしても、レコメンドシステムにしても、モデルの予測にユーザーの希望が反映されるように微調整や整合を行うことで、利便性が格段に上がります。
LLMの場合、アライメントデータの収集は比較的容易です。明示的なフィードバックに依存しており、人間が出力に対して直接判断を下します:
- 嗜好アノテーション:アノテーターが候補の順位付けや質の評価を行い、明確な監視信号を送ります。
- インタラクティブな選択:最近では、チャットのやり取りからフィードバックが収集されるようになり、ユーザーは候補を比較して選択することも、ミスを修正して改善するための情報を入力することもできます。
- 明確な意図:判断がはっきりと下されるため、モデルはどの回答が好まれているかを正確に把握でき、それに応じて最適化できます。
レコメンドシステムにおいては、整合性を高めるためのデータ収集ははるかに複雑です。ユーザーの行動が明示的に示されておらず、解釈の必要がある暗黙的フィードバックを利用することになるため、さまざまな課題が生じます:
- フィードバック不足や偏見を含むフィードバック:提案された商品に関する結果のみが観測され、表示される可能性があった候補については結果が観測されません。新しいポリシーを評価するには、「商品 A ではなく B が表示されていたらとどうなっていたか?」などの反実仮装的な問いにに回答する必要があります。
- 信頼性の低いシグナル:フィードバックがあったとしても、その意図がはっきりしません。表示されている商品のほとんどがクリックされていないとしても、関連性が低いからなのか、タイミングが悪かったからなのか、発見可能性が低かったからなのかは不明です。また、シグナルが遅れて届くことが多く、実際の効果は何週間も遅れて、購入やサブスクリプション、ロイヤルティの向上といった形で表れます。
- カタログのサイズと離反:フィードバックは膨大なアイテム群に薄く分散しており、そのアイテム群は絶えず変化しています。数百万もの商品が時間とともに登場し、消えていきます。
このような違い(図3参照)により、レコメンドシステムでのパフォーマンスのアライメントと LLM におけるアライメントは、根本的に異なる課題となります。LLM は明示的な嗜好データを活用できますが、レコメンドシステムは欠落やノイズの多いシグナル、遅延する成果、そして膨大で絶えず変化するカタログと格闘しなければなりません。
暗黙的フィードバックからの反実仮想学習に関する研究(2015年、Swaminathan と Joachims )では、レコメンドの反事仮装的評価や最適化の難しさと必要性を強調しています。Criteo は、オフポリシー評価(2018年 WSDM、Gilotte A他)、因果埋め込み(2018年 RecSys、Bonner と Vasile )、およびレコメンド向けの反実仮想学習の進化(2020年 KDD、Jeunen O 他)などを先駆的に導入し、この課題に真正面から取り組んできました。
また、これを基盤に、分布ロバストな反実仮想リスクの最小化(2020年 AAAI、Faury 他)、大規模な商品レコメンド向けの迅速なオフラインポリシー最適化(2022年 AAAI、Sakhi 他)、保証付きオフライン・コンテキスト・バンディット(2023年 ICML、Sakhi 他、2023年 ICML、Aouali 他)、そして最近では、対数スムージングのような悲観的オフポリシー手法(2024年 NeurIPS、Sakhi, O. と Aouali, I )と、未開拓の研究分野に踏み込んでいます。これらの取り組みにより、Criteo はレコメンド向けの理論的根拠に基づいた堅牢なオフポリシー学習において業界を牽引し、原理評価と実際の運用における拡張性の間のギャップを埋められるよう取り組んでいます。
なぜ LLM はレコメンドシステムをまだ置き換えられないのか
LLM への期待は大きいものの、現段階の商品レコメンドにおいて、LLM には構造的な壁があります。
- カタログの規模:商品カタログは言語の語彙を圧倒的に上回る規模があり、しかも常に変化しています。そのため、LLM には絶えず入れ替わる商品を追跡し、適切な商品を大規模に提示できる外部検索エンジンが必要です。
- データとフィードバック:ファインチューニングにライブトラフィックが必要で、お金も時間もかかります。クリックや購入といったシグナルはまばらで遅延があり、ノイズも多いため、イテレーションサイクルが長く、高価になります。
- ファインチューニングの性質:コマースにまつわるフィードバックはほとんどが暗黙的であいまいなため、モデルを適切に調整するためには、反事実学習やバンディット手法といった高度なアプローチが必要です。これは、LLM に一般的に使われる教師ありファインチューニングのパイプラインと比べて、はるかに複雑です。
このような理由により、現段階では LLM ベースのレコメンドは大規模運用には不向きです。LLM の強みである推論と説明はレコメンドシステムのパフォーマンスや拡張性を補足することはできても、代替することはできません。
このような制約は、RecSys(レコメンドシステム)関連の文献や当社の研究における実証結果にも一貫して表れています。 Criteo のメタレビュー「Can LLMs Recommend as well as Modern RecSys?(LLM は現代のレコメンダーシステムと同様に商品を推薦できるのか)」にも詳しく書かれている通り、レコメンド専用のアーキテクチャに匹敵するようなパフォーマンスが最適化された商品レコメンドを、現在の LLM が単独で提供することはできないのです。
ハイブリッドなアプローチ:パフォーマンス最適化されたレコメンド・エージェント
レコメンドの未来は、ハイブリッドシステムにあります。このアプローチの基盤となるアーキテクチャが2020年に Lewis 他が紹介したRetrieval-Augmented Generation(検索拡張生成、RAG)で、検索エンジンを生成モデルに重ね、関連する外部データに基づいた出力を生成します。
このアーキテクチャは、商品レコメンドにおけるエージェント型の仕組みとして捉えられます。LLM は、パフォーマンスベースのレコメンドシステムをツールとして活用する、インテリジェントなエージェントとして動作します。具体的には、レコメンドシステムにクエリを送り、上位候補を取得して、推論と絞り込みを行い、自然言語で選択理由を説明します。
具体的には、ハイブリッドシステムは以下の2つの緊密に連携したレイヤーの中で運用されます:
- ビジネス KPI に最適化された、パフォーマンスの高い候補を取得するレコメンドシステムの基盤
- ユーザーの意図を解釈し、「50ドル以下」や「エコフレンドリー」といった固有の条件を適用して、自然言語の説明を生成するLLM の推論レイヤー
この2つのレイヤーを組み合わせることで、商品レコメンドシステムの拡張性やパフォーマンスに、LLM の対話性と説明力が加わり、次世代のコマースレコメンドの基盤を作ることができます。
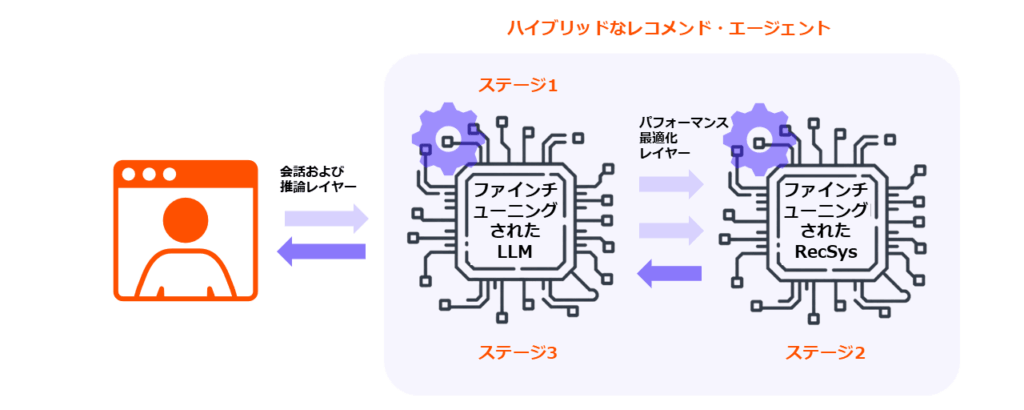
図4:3つのステージに分かれたハイブリッド・エージェント:LLM が意図を解釈して推論を提供します。一方、レコメンドシステムのエンジンが検索とランキングのパフォーマンスを最適化して、対話型のインテリジェンスと大規模な最適化を両立させます。
3ステージでフィードバックループを完結させるエージェント
図4で示す通り、ハイブリッド・エージェント3つの明確なステージで動作します:
- 意図の理解:LLM がユーザーのニーズを解釈し、構造化された商品クエリに変換します。
- 検索と順位付け:レコメンドシステムが、指定されたクエリにおいて最もパフォーマンスの高い商品の候補を予測します。
- 推論と説明:LLM がフィルターを適用し、トレードオフを調整して、選択した内容について説明します。
この3つのステージが組み合わさり、フィードバックループが完成します。ユーザーとやり取りを重ねるごとにシステムは改善され、レコメンドの精度と信頼性が日を追うごとに高まります。
市場へのインパクト
レコメンドシステムと LLM の融合は、デジタルコマースの重要な転換期となる可能性があります。どちらの技術もそれぞれの軸で優れています。レコメンドシステムはパフォーマンスを、LLM は推論を提供します。ただし、どちらも単独では不十分です。
ハイブリッドモデルの登場により生まれる新たなカテゴリー、それが「インテリジェントなエージェント」です。拡張性が高く、リアルタイムのデータに基づき、透明性の高い意思決定を行うことができるエージェントです。
市場にとって、これはふたつの大きな変化を意味します:
- 信頼が差別化要因に:消費者が透明性を求めるようになるため、提案内容の根拠を示せるシステムが、エンゲージメントを勝ち取り、規制でも優位に立てます。
- AI が成長のカギを握るレバーに:ハイブリッドなレコメンド・エージェントは、単なるインフラにとどまりません。測定可能な ROI をファネル全体にもたらす戦略的なアセットとなります。
Criteo では、このサイクルにおける3つのステージ(意図の理解、候補の抽出、推論と説明)すべての構築に積極的に取り組んでいます。一つひとつのやり取りがループを強化し、スマートな商品レコメンドを促進して、効率や信頼性を高めます。パフォーマンスに基づく抽出と LLM ベースの推論を組み合わせることで、Criteo は次世代のコマースレコメンドを定義するハイブリッドアーキテクチャを創り出しています。これは単なる技術的な変化でなく、ビジネスの成長や消費者の意思決定における新たな基盤となるものです。
しかし、サイロ化された環境では、コマースの規模を拡大できません。ウォールドガーデンや1対1のパートナーシップはエコシステムを断片化してしまいます。Criteo は、真逆のアプローチを取っています。つまり、リテーラーやブランド、プラットフォームを共有ネットワークでつなげる多対多のアーキテクチャです。新たな参加者が増えるほど効果が強化されていくため、このマーケットプレイス効果は時間とともに複利的に作用し、成果を増幅させます。
Criteo は、コマースレコメンドの未来を形作る独自のポジションにあります。これからのレコメンドは、技術的な進化だけでなく、エコシステム全体の進化を意図したハイブリッドシステムになっていくのです。
さらに詳しくは、関連資料「How RecSys & LLMs Will Converge: Architecture of Hybrid RecoAgents(商品レコメンドシステムと LLM の融合:ハイブリッド・レコメンド・エージェントのアーキテクチャ)」をご覧ください。次世代エコシステムの裏にある計画について詳細に説明しています。






